Context-Dependent Sentence Detection in LLM Caching Pipelines

Building an effective caching pipeline is extremely important to keep costs down and improve the user experience by lowering latency. However, we'll run into one pesky issue immediately: How do we determine which user prompts to cache, and which to ignore?
For example: Say you have a user question "Why is the sky blue?" and "Why is it blue?" The user references a previous context which we don't have access to. We don't want to cache that question and response pair, as doing so would pollute the cache with semantically irrelevant data - in other words: responses that don't necessarily apply to the user's question.
What we need is to determine if a sentence is context dependent or is self-contained. Natural Language Processing to the rescue!
In this blog I'll describe a few ways we can determine context dependency - using my favorite NLP library; SpaCy.
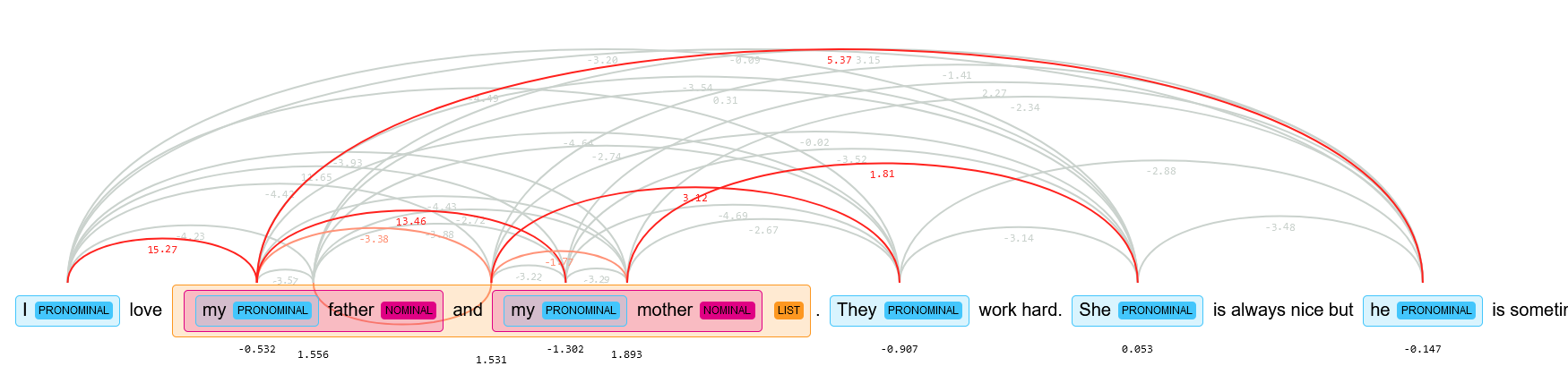
Coreference Resolution
In short, coreference is the fact that two or more expressions in a text – like pronouns or nouns – link to the same person or thing. It is a classical Natural language processing task, that has seen a revival of interest in the past two years as several research groups applied cutting-edge deep-learning and reinforcement-learning techniques to it.
This can help us determine if a sentence is context dependent by the fact that a coreference is not resolved.
SpaCy recently added a coreference model, trained in English on the OntoNotes dataset, it inferences on GPU and therefore adds some latency.
import spacy
nlp = spacy.load("en_core_web_trf")
nlp.add_pipe("coreferee")
def has_unresolved_coreference(text):
doc = nlp(text)
return any(token._.coref_chains for token in doc)
# Example usage
text = "Why is it blue?"
print(f"Has unresolved coreference: {has_unresolved_coreference(text)}")
Named Entity Recognition (NER)
NER is another valuable tool in our arsenal. By identifying and categorizing named entities such as people, organizations, and locations, we can better understand the key players in a sentence. If a sentence heavily relies on named entities introduced earlier in the text, it's likely not context-dependent and can be cached independently.
import spacy
nlp = spacy.load("en_core_web_sm")
def has_named_entities(text):
doc = nlp(text)
return len(doc.ents) > 0
# Example usage
text = "John works at Google in New York."
print(f"Has named entities: {has_named_entities(text)}")
Dependency Parsing
Dependency parsing allows us to analyze the grammatical structure of a sentence and understand the relationships between words. By examining the dependency tree, we can identify if a sentence contains references to elements outside its own scope. For instance, if a sentence has a pronoun as the subject without a clear antecedent within the same sentence, it suggests context-dependency.
import spacy
nlp = spacy.load("en_core_web_sm")
def has_external_dependency(text):
doc = nlp(text)
return any(token.dep_ == "nsubj" and token.pos_ == "PRON" for token in doc)
# Example usage
text = "He went to the store."
print(f"Has external dependency: {has_external_dependency(text)}")
Noun Phrase Extraction
Noun phrase extraction is particularly useful for identifying self-contained sentences. If a sentence contains complete noun phrases without relying on external references, it's more likely to be context-independent and suitable for caching. spaCy's can extract noun phrases to help us here.
import spacy
nlp = spacy.load("en_core_web_sm")
def has_complete_noun_phrases(text):
doc = nlp(text)
noun_phrases = list(doc.noun_chunks)
return len(noun_phrases) > 0
# Example usage
text = "The quick brown fox jumps over the lazy dog."
print(f"Has complete noun phrases: {has_complete_noun_phrases(text)}")
Part-of-Speech Tagging (POS)
Part-of-speech (POS) tagging is another fundamental feature of spaCy that aids in context-dependent sentence detection. By analyzing the POS tags of words in a sentence, I can identify patterns that suggest context-dependency. For example, if a sentence starts with a pronoun or a conjunction, it often indicates a connection to the previous context.
import spacy
nlp = spacy.load("en_core_web_sm")
def starts_with_pronoun_or_conjunction(text):
doc = nlp(text)
first_token = doc[0]
return first_token.pos_ in ["PRON", "CCONJ", "SCONJ"]
# Example usage
text = "But they didn't know about it."
print(f"Starts with pronoun or conjunction: {starts_with_pronoun_or_conjunction(text)}")
Putting it all together
By leveraging these linguistic features provided by spaCy, we can build a robust LLM caching pipeline that intelligently determines which sentences to cache and which to ignore. Coreference resolution helps identify sentences that rely on previous mentions of entities, while NER highlights sentences heavily dependent on named entities. Dependency parsing uncovers grammatical dependencies that extend beyond the sentence itself, and noun phrase extraction identifies self-contained sentences suitable for caching. Finally, POS tagging provides additional insights into the structure and context-dependency of sentences.
By combining these approaches in a weighted fashion, we get the best of all worlds. See below for test results.
import spacy
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe("coreferee")
def is_context_dependent(text):
doc = nlp(text)
# Coreference Resolution
has_unresolved_coref = any(token._.coref_chains for token in doc)
# Named Entity Recognition
has_entities = len(doc.ents) > 0
# Dependency Parsing
has_external_dep = any(token.dep_ == "nsubj" and token.pos_ == "PRON" for token in doc)
# Noun Phrase Extraction
has_noun_phrases = len(list(doc.noun_chunks)) > 0
# Part-of-Speech Tagging
starts_with_pron_conj = doc[0].pos_ in ["PRON", "CCONJ", "SCONJ"]
# Combine all factors to determine context dependency
is_dependent = (
has_unresolved_coref or
has_entities or
has_external_dep or
not has_noun_phrases or
starts_with_pron_conj
)
return is_dependent
# Example usage
sentences = [
"The sky is blue.",
"Why is it blue?",
"John works at Google in New York.",
"He went to the store.",
"The quick brown fox jumps over the lazy dog.",
"But they didn't know about it."
]
for sentence in sentences:
print(f"Sentence: '{sentence}'")
print(f"Is context-dependent: {is_context_dependent(sentence)}\n")
Test Results
Sentence: 'The sky is blue.'
Is context-dependent: False
Sentence: 'Why is it blue?'
Is context-dependent: True
Sentence: 'John works at Google in New York.'
Is context-dependent: False
Sentence: 'He went to the store.'
Is context-dependent: True
Sentence: 'The quick brown fox jumps over the lazy dog.'
Is context-dependent: False
Sentence: 'But they didn't know about it.'
Is context-dependent: True
Further Reading
[1] Spacy's coreference training: https://explosion.ai/blog/coref
[2] Huggingface's coreference model: https://github.com/huggingface/neuralcoref
[3] Neural Mention Detection: https://aclanthology.org/2020.lrec-1.1.pdf