Detecting LLM writing in Text

LLMs are harder and harder to detect in text, and detection vary between models. In this article I will explore a couple of easy and hard methods to find LLM generated text. This is not foolproof so please don't rely on it.
Linguistic and Stylistic Recognition
First, detecting AI-generated text requires examining specific linguistic patterns and stylistic conventions that emerge from how language models construct responses. These patterns often reflect the training methodologies and optimization objectives of modern LLMs.
Promotional and Emphatic Language Patterns
AI models frequently exhibit characteristic language patterns that reveal their AI origin. They overemphasize significance and importance through repetitive phrases like "stands as a testament," "plays a vital role," or "underscores its importance." This pattern emerges because training data often includes promotional content, and models learn to associate certain topics with elevated language.
The tendency toward promotional language becomes particularly pronounced when AI systems write about cultural topics, locations, or historical subjects. Phrases like "rich cultural heritage," "breathtaking landscapes," and "enduring legacy" appear with suspicious frequency. Human writers typically vary their descriptive language more naturally and avoid superlatives (unless they think very highly of themselves).
Editorial Voice and Opinion Injection
Language models struggle with maintaining neutral perspective, often injecting editorial commentary through phrases like "it's important to note" or "no discussion would be complete without." This reflects their training on diverse text sources including opinion pieces, blogs, and analytical content.
The models frequently present subjective assessments as factual statements, using constructions like "defining feature" or "powerful tools" without proper attribution. Human writers generally maintain clearer boundaries between factual reporting and interpretive analysis.
Structural and Formatting Conventions
AI-generated text exhibits distinctive structural patterns that differ from natural human writing conventions. These include consistent overuse of certain conjunctive phrases like "moreover," "furthermore," and "on the other hand." While human writers use these connectors, AI systems employ them with mechanical regularity.
Section summaries represent another telltale pattern. AI models frequently conclude paragraphs or sections with explicit summaries beginning with "In summary" or "Overall." This academic essay structure rarely appears in natural prose outside formal academic contexts.
Typographical and Markup Indicators
Technical indicators provide some of the most reliable detection signals. AI systems often generate text using markdown formatting rather than appropriate markup for the target platform. Bold text appears through asterisk formatting instead of proper HTML or wiki markup.
Curly quotation marks and apostrophes frequently appear in AI generated text, contrasting with the straight quotes typically used in digital writing. Most human writers use straight quotes because they're the default on standard keyboards, making curly quotes a strong indicator of machine generation.
Reference and Citation Anomalies
AI models exhibit characteristic problems with citations and references that provide clear detection signals. They frequently generate plausible-looking but non-existent references, complete with realistic journal names, authors, and publication details.
Invalid DOIs and ISBNs appear regularly in AI-generated citations. While these identifiers include checksums that can be automatically verified, AI models often generate syntactically correct but mathematically invalid identifiers.
The models also demonstrate poor understanding of citation reuse conventions, creating malformed reference syntax when attempting to cite the same source multiple times within a document.
Conversational Artifacts and Prompt Leakage
AI systems sometimes include conversational elements intended for the human user rather than the final document. Phrases like "I hope this helps," "let me know if you need more information," or "here's a detailed breakdown" indicate text copied directly from a chatbot interaction.
Knowledge cutoff disclaimers represent another clear indicator, with phrases like "as of my last training update" or "as of [specific date]" revealing the AI's awareness of its training limitations.
Prompt refusal text occasionally appears in AI-generated content, including apologies and explanations about being "an AI language model." These artifacts suggest the human editor copied text without careful review.
Template and Placeholder Patterns
AI models sometimes generate template text with placeholder brackets for human customization. Phrases like "[Subject's Name]" or "[URL of source]" indicate incomplete AI-generated content that wasn't properly customized before publication.
These templates often follow Mad Libs-style patterns where specific details should be filled in by the human user. When these placeholders remain unfilled, they provide unambiguous evidence of AI generation.
Technical Artifacts from Specific Platforms
Different AI platforms leave characteristic technical fingerprints in their output. ChatGPT may include reference codes like "citeturn0search0" or "contentReference[oaicite:0]" when the platform's citation features malfunction.
URL parameters like "utm_source=chatgpt.com" appear when AI systems include links that retain tracking information from their training data or web searches.
These platform-specific artifacts change as AI systems evolve, requiring detection systems to stay current with the technical peculiarities of different models and platforms.
Going beyond: Statistical Approaches (math heavy, sorry!)
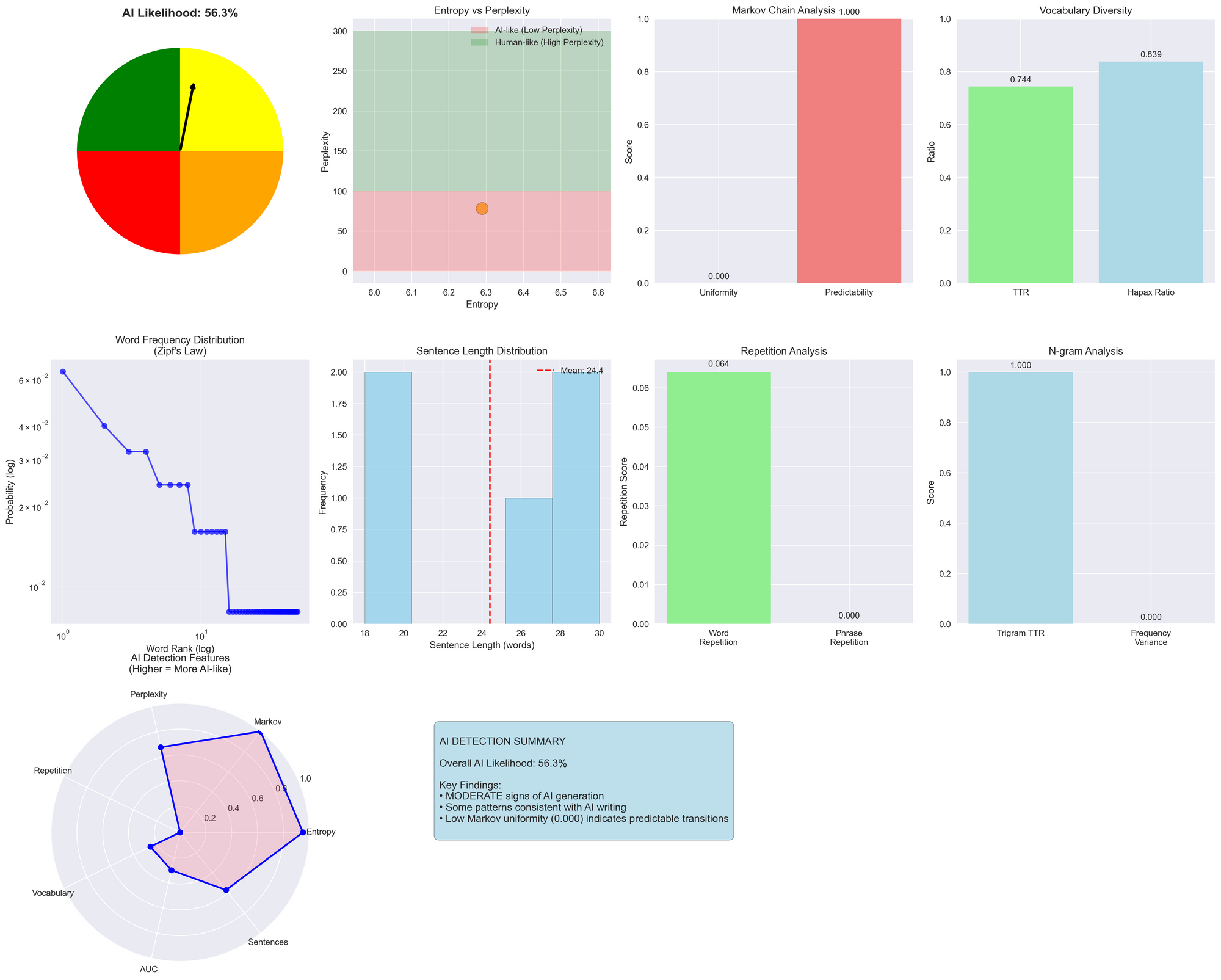
Entropy and Perplexity Analysis
Entropy measures the randomness in word choice patterns. Human writing typically exhibits higher entropy due to varied vocabulary and unpredictable word sequences. LLMs often produce lower entropy text because they select words based on probability distributions learned during training.
Perplexity quantifies how well a probability model predicts text samples. Lower perplexity indicates more predictable text patterns. AI-generated content frequently shows reduced perplexity compared to human writing, as models tend to favor common word combinations and avoid unusual phrasings that humans might naturally use.
The calculation involves measuring the cross-entropy between predicted and actual word distributions. A text with perplexity of 50 means the model is as confused as if it had to choose uniformly among 50 possibilities at each step.
Markov Chain Transition Analysis
This technique examines the probability patterns of word sequences. Human writing shows more variation in transition probabilities between word pairs or triplets. LLMs often exhibit more uniform transition patterns due to their training on large, homogenized datasets.
The method constructs transition matrices for n-gram sequences and analyzes the uniformity of probability distributions. High uniformity in transitions suggests AI generation, while irregular patterns indicate human authorship. Second-order Markov analysis (examining word triplets) proves particularly effective for this detection approach.
N-gram Frequency Distribution
N-gram analysis examines the frequency patterns of word sequences. Human text typically follows Zipf's law more closely, where word frequencies follow a power-law distribution. AI-generated text often deviates from these natural patterns.
The type-token ratio (TTR) for n-grams provides another detection signal. Human writing maintains higher TTR values, indicating greater diversity in phrase construction. LLMs frequently repeat similar n-gram patterns, resulting in lower TTR scores.
Trigram analysis proves especially useful because it captures local coherence patterns while remaining computationally tractable. Examining trigram variance helps identify the repetitive patterns common in AI-generated text.
Vocabulary Diversity Metrics
The Measure of Textual Lexical Diversity (MTLD) calculates how quickly vocabulary diversity decreases as text length increases. Human writing maintains lexical diversity across longer passages, while AI text often shows declining diversity.
MTLD works by tracking the type-token ratio as text progresses and counting how many words are needed before the ratio drops below a threshold (typically 0.72). Higher MTLD scores suggest human authorship.
Hapax legomena analysis examines words that appear only once in a text. Human writing typically contains more unique words, while AI models tend to reuse vocabulary more frequently due to their probabilistic nature.
Area Under the Curve (AUC) Methods
AUC analysis examines the cumulative probability distribution of word frequencies. Natural human text follows predictable curves when plotting cumulative word frequency against rank. AI-generated text often produces different curve shapes.
This approach involves sorting words by frequency, calculating cumulative probabilities, and measuring the area under the resulting curve. Deviations from expected AUC values indicate potential AI generation.
The method also incorporates Zipf's law analysis by examining the slope of log-frequency versus log-rank plots. Natural text typically shows slopes near -1, while AI text often deviates significantly from this value.
Repetition Pattern Detection
AI models frequently exhibit subtle repetition patterns that humans rarely produce. These include repeated phrase structures, similar sentence beginnings, or cyclical vocabulary usage.
Detection algorithms scan for phrase-level repetitions across different text segments. They calculate repetition scores by identifying recurring multi-word sequences and measuring their frequency relative to text length.
Sentence structure analysis complements phrase repetition detection by examining syntactic patterns. AI text often shows more uniform sentence structures compared to the varied constructions in human writing.
Conclusion
Thats all folks! Thanks for coming to my TED talk.